Preface
I have some strongly-held beliefs about commit messages in VCS. For obvious reasons, I tend to use git - but I believe that the core ideas extend to any VCS and are not specific to git.
That being said, I can’t say that I always follow this guide - like any other human, I am prone to mistakes, and some things don’t warrant such care.
Bad examples of commit messages, ahead of time, for transparency:
- oops
- … lol
- updated vimrc
- “i need to remember things” instead of actually writing something useful
I know that there are more bad examples, but first let me share what I think looks good.
Commit Message Style
For commit style, I like to follow a similar style to the Linux Kernel guidelines; not strictly, but close to it. My preference looks like the following:
feature or affected pkgs: one-line general description, 80 chars max
Details about what you did and why, rationale behind the changes. If the line
would flow past 80 chars, newline and continue.
If there are multiple things addressed in a single commit, separate with
paragraphs to explain them individually.
refs, fixes or closes [reference to ticket]
A real-world example of this in the go repo:
go/types, types2: fix string to type parameter conversions
Converting an untyped constant to a type parameter results
in a non-constant value; but the constant must still be
representable by all specific types of the type parameter.
Adjust the special handling for constant-to-type parameter
conversions to also include string-to-[]byte and []rune
conversions, which are handled separately for conversions
to types that are not type parameters because those are not
constant conversions in non-generic code.
Fixes #51386.
Rebase Guidelines
Git history is important is pretty important to me. I want to know, at a glance, what was worked on and the general description.
If I use git log or jump into more detailed history (tig), for nontrivial
commits, I should see some rationale or details that should give me enough info
to understand the problem.
There are several real-world examples of what I disagree with, but I don’t want to call anyone out - and I imagine that you’ve seen things similar to the following:
fix typo- where? why is this a distinct commit?oops- what was wrong?add test- for what?update- what was updated and why?fixes #001- what exactly was 001? Tickets can be edited or simply not have decent details in the first placeaddress review comments- why is this a distinct commit?rebase,merge- conflicts, what happened?lint fixes- update the offending commit!
Something to note here, however, is that some level of this is acceptable during development. Commit early, commit often. That being said, cleanup is a constant process - you don’t clean up your home once a month, clean up messes as you go.
Once this makes it to the master branch, it’s frozen - unless you rewrite history, which I strongly discourage and would frown at.
How to Rebase effectively
Git rebase is very simple to take advantage of and offers a lot of ways to make commit history grokable. This should be done prior to merging into the master branch.
A workflow could look something like this:
- initial commit
- added something
- forgot to add something, so committed it
- test
- update test
- oops messed up test
To fix this up, we’ll use git rebase, specifically in interactive mode, which
is super easy to deal with.
Subsequently, getting a good history:
$ git rebase -i HEAD~6
$ < editor opens >
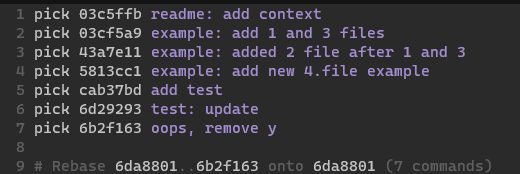
You’ll see something like the following:
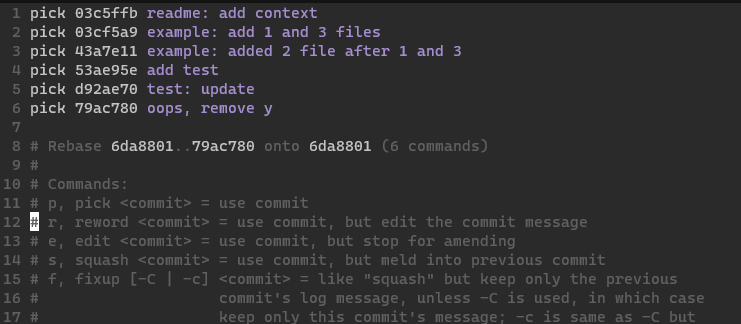
Here, we want to:
- group
03cf5a9and437ae11 - group
53ae95e...79ac780- these are all test related and initial work, might as well
Using the nice commands, we use:
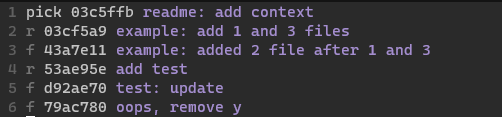
We choose:
rewordon03cf5a9- we’re merging the next commit; update the commit message to mention file 2fixupon43a7e11rewordon53ae95e- we’re merging the next commit; update the commit message to add the proper prefixfixupon the last two
The resulting history is cleaner in branch ex/rebase than in master.
Another really nice thing about rebase is the ability to re-order commits. In this example, if we had added a commit later to add a new file:
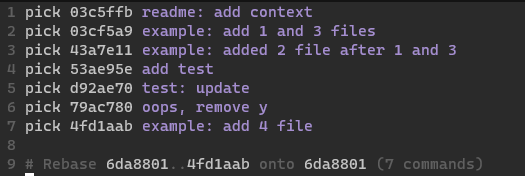
We can now choose to move this add 4 file commit to the relevant section and
merge it into the previous commits:
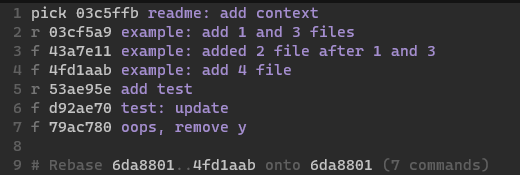
We moved 4fd1aab above the tests so that it’s grouped with others and chose to
merge it with those - preventing a “random” example: commit later on
ex/rebaseorder.
This isn’t always necessary, mind you. Let’s imagine for a moment that this is a significant commit and we don’t want to merge it with the other examples. In this case, simply reordering it is fine as in ex/rebaseorder2.
Leaving it there would be acceptable.